本文内容导航
文档理解
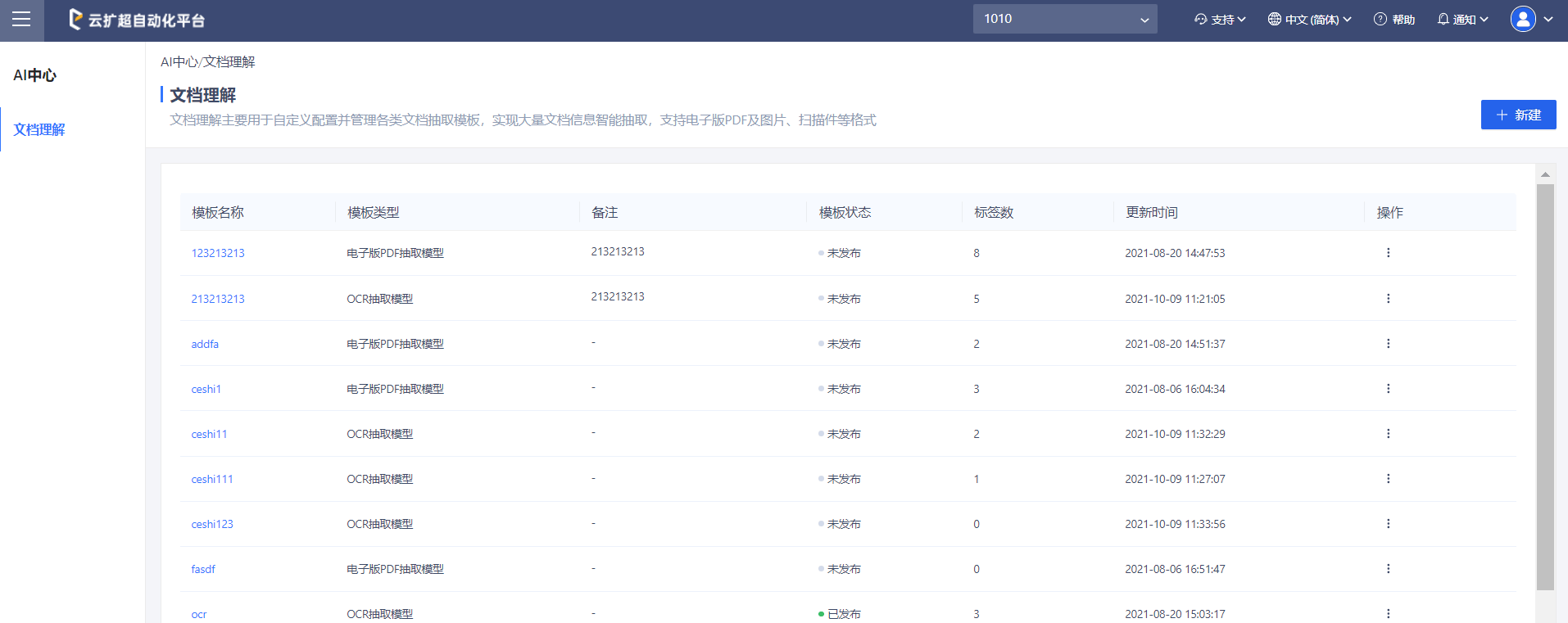
查看文档理解模板列表
进入“文档理解”页面中即可通过列表查看当前资源组下所有的文档理解模板。主要包括模板名称、模板发布状态以及当前模板的抽取标签等信息。模板主要用于对属于该模板的同类文件进行非结构化信息抽取。
新建文档理解模板
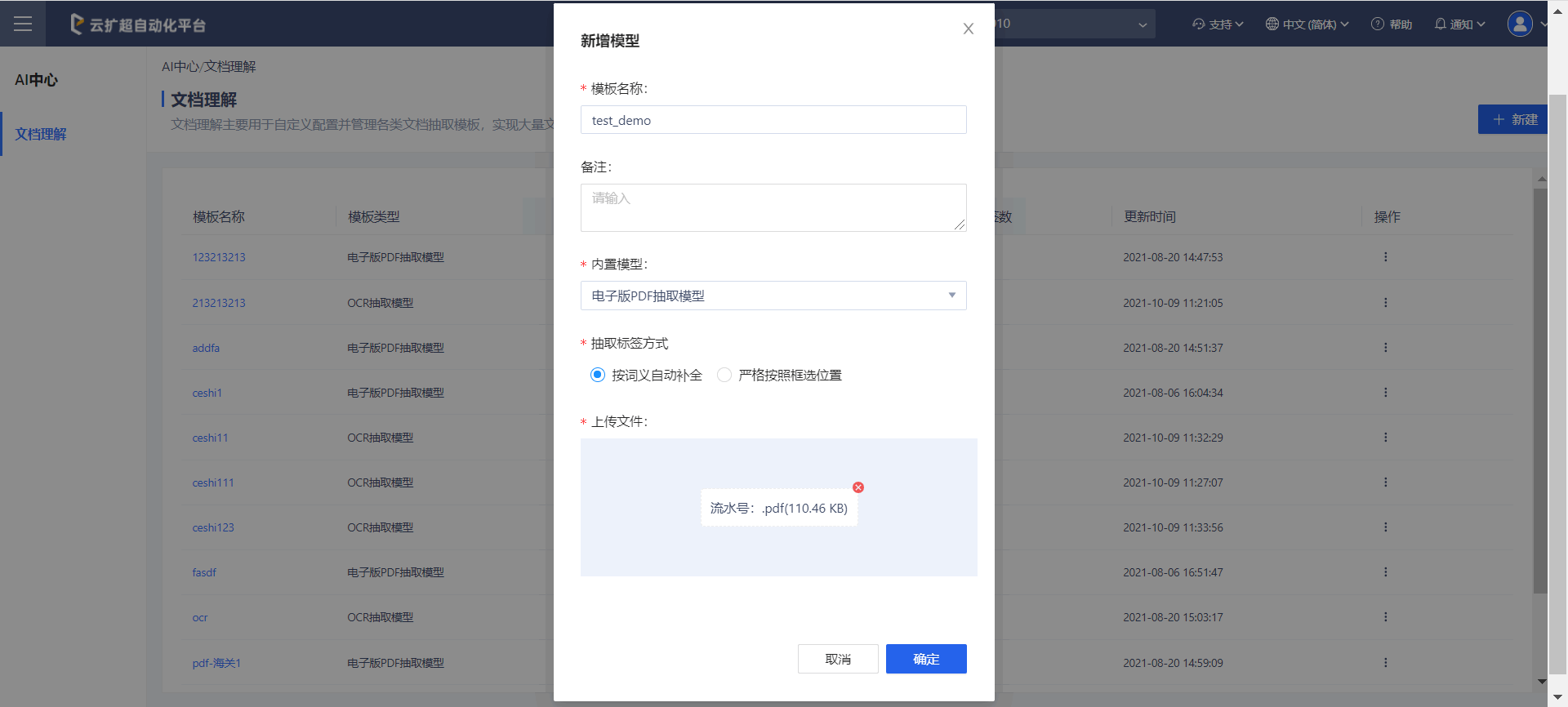
新建文档理解模板点击“新建”按钮,在弹窗中填写模板名称、备注、选择内置模型(包括电子版 PDF 抽取模型、OCR 抽取模型)选择对应的模板文件之后即可完成模板信息的初步创建。
说明:
当内置模型选择“电子版PDF模型”时,可选择不同的“抽取标签方式”。
配置文档理解模板
文档理解模板配置
配置文档理解模板主要由用户通过可视化界面自定义配置文本信息的抽取区域,用户可通过拉框选定的方式确定需要进行抽取的文本区域。
文件锚点配置
文件锚点用于对文件进行模板匹配及倾斜校正,通过点击附件上的“灰色文本区域 " 的方式确定文件锚点。锚点必须要是不变的文字,每页锚点不得少于 3 个,越多越好。
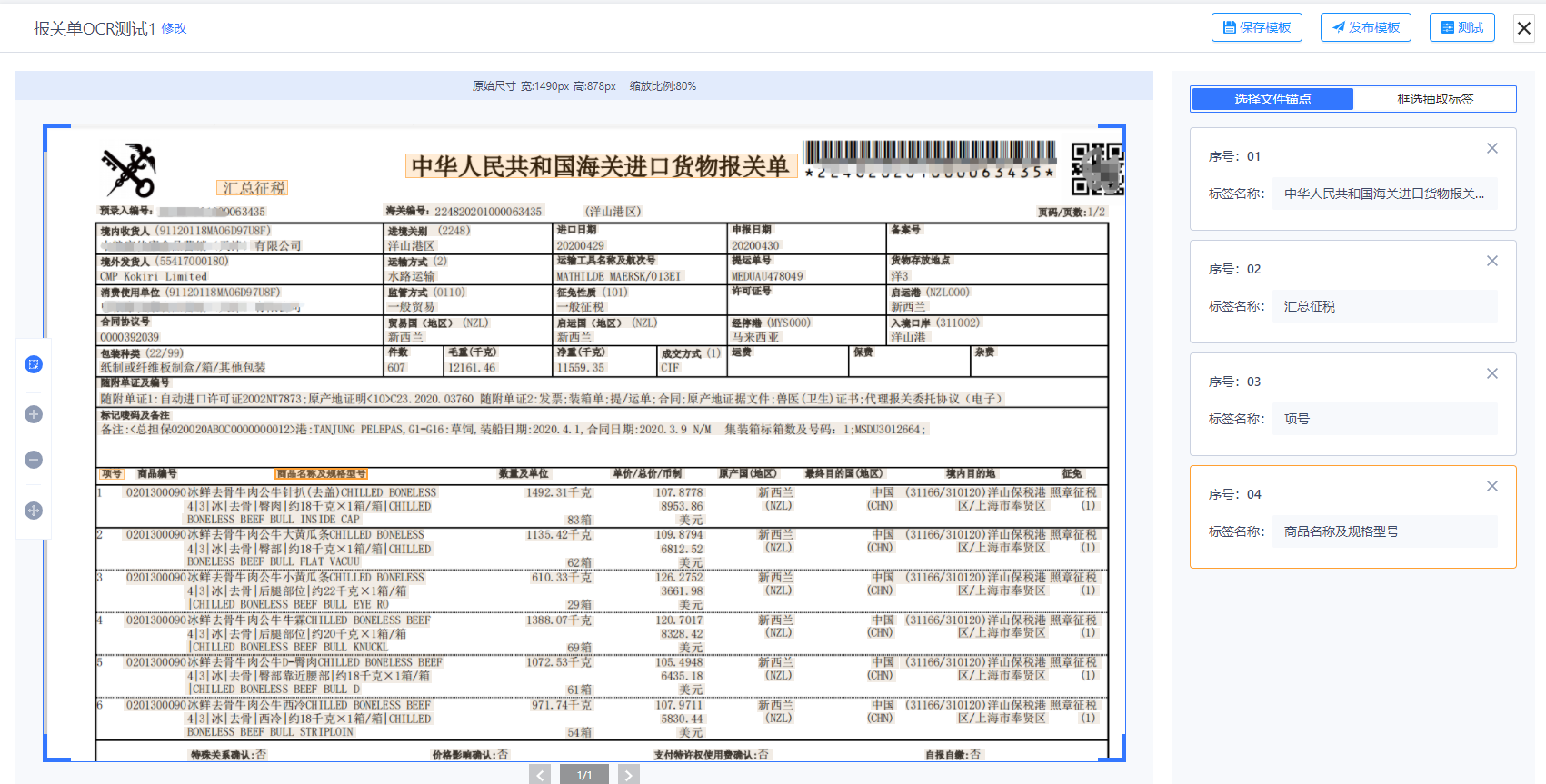
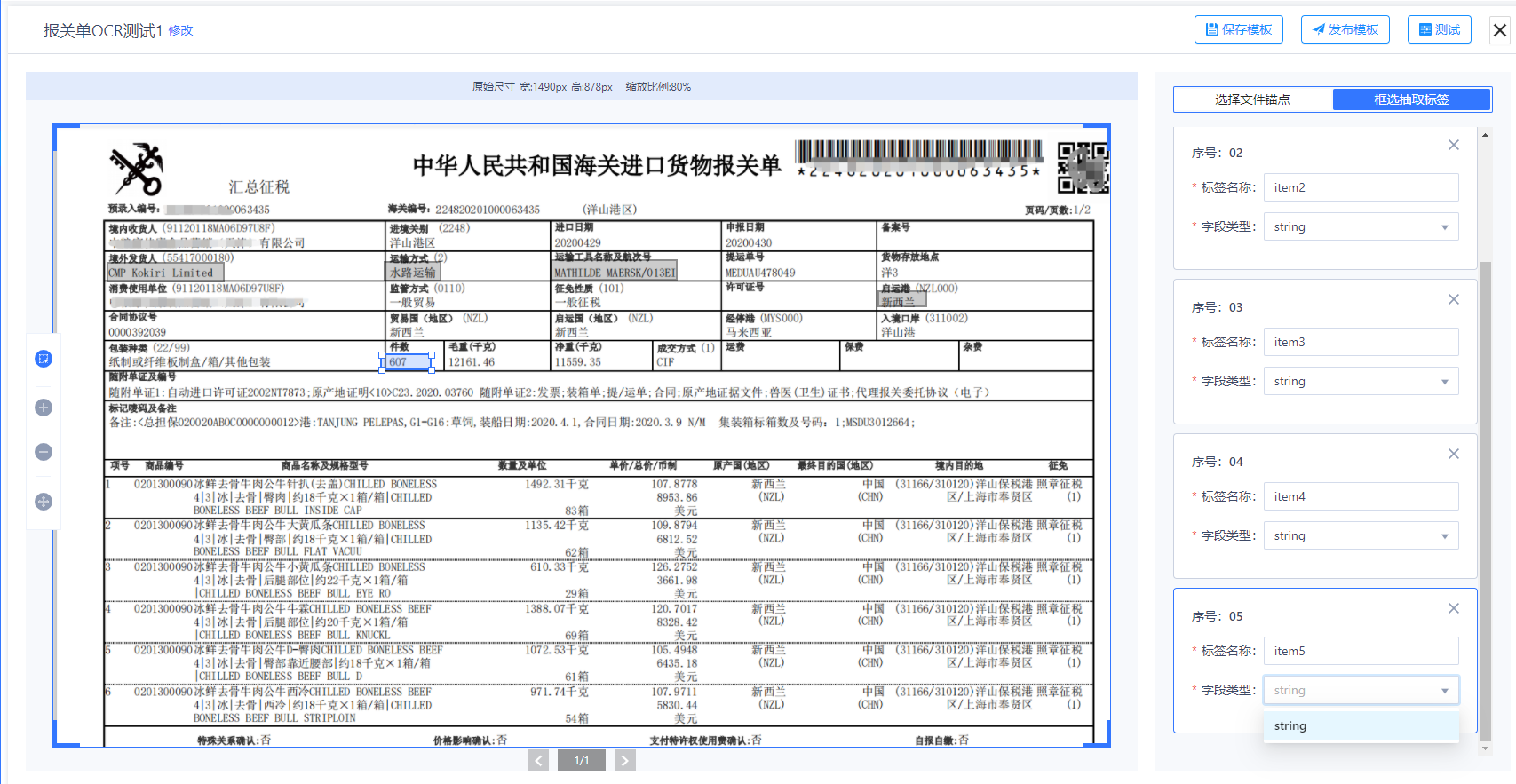
抽取标签配置
可以通过鼠标拉框方式在附件展示区域选定要抽取的文字区域,每选定一个区域将自动新增一个标签。 每一个标签意味着一个非结构化文本抽取区域,批量抽取过程将按照标签输入对应文本内容。
标签渲染
点击某一标签时候,高亮显示点击项,同时高亮显示附件中的框选区域。选择某一个标记框时,标记框高亮显示,同时高亮显示对应的标签。
电子版 PDF 文档理解模板配置
配置文档理解模板主要由用户通过可视化界面自定义配置文本信息的抽取区域,用户可通过拉框选定的方式确定需要进行抽取的文本区域。
抽取标签配置
可以通过鼠标拉框方式在附件展示区域选定要抽取的文字区域,每选定一个区域将自动新增一个标签。 每一个标签意味着一个非结构化文本抽取区域,批量抽取过程将按照标签输入对应文本内容。
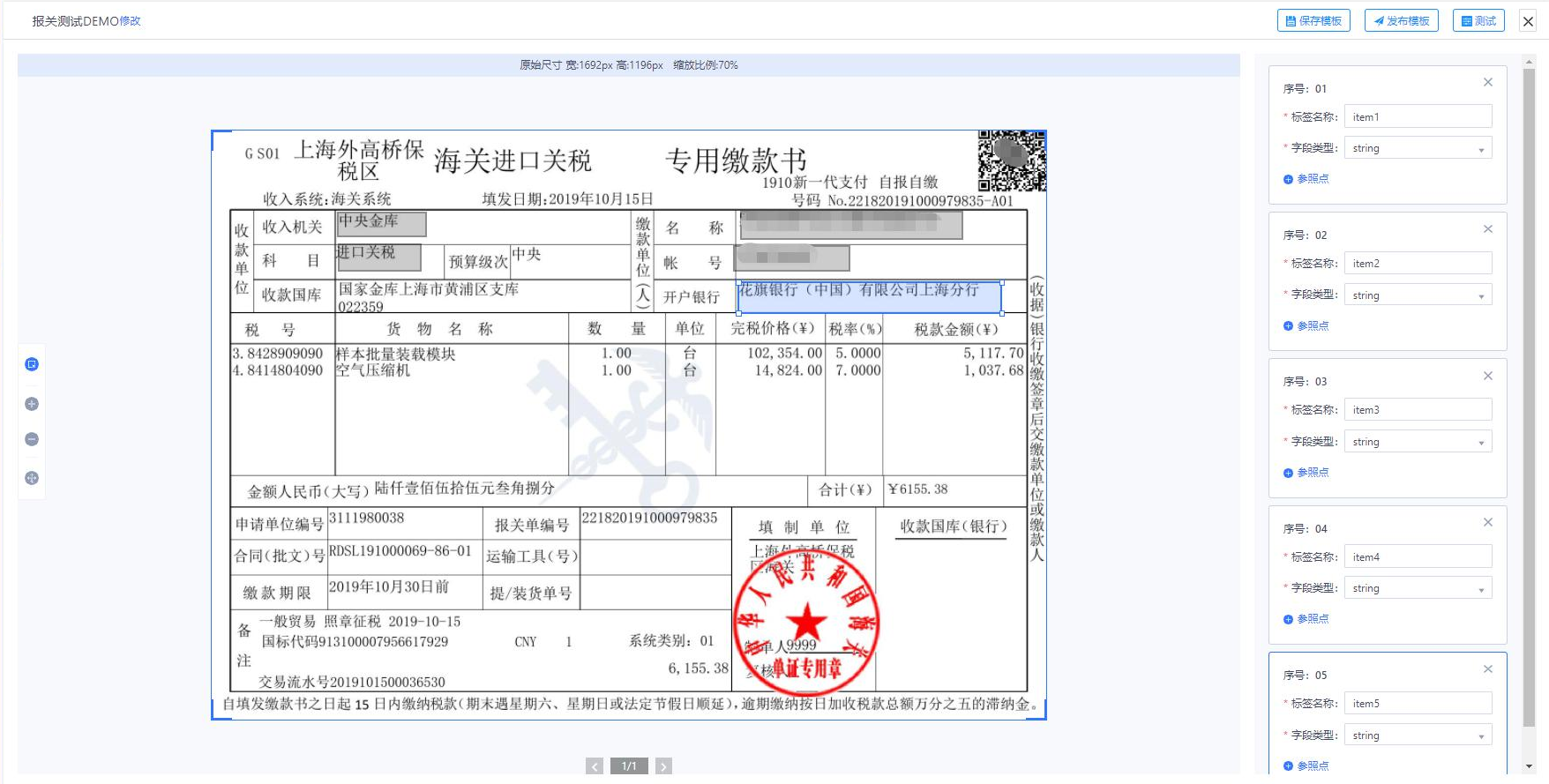
参照点配置
若标签抽取区域在文本中的位置会出现一定偏差,可通过对单个标签新增参照点以辅助对新样本进行信息抽取时的抽取框定位。点击“参照点“按钮,在展开的区域中填写参照点的内容并选择参照点的方向
- 上:参照点在标签框的上方
- 下:参照点在标签框的下方
- 左:参照点在标签框的左方
- 右:参照点在标签框的右方

标签渲染
点击某一标签时候,高亮显示点击项,同时高亮显示附件中的框选区域。选择某一个标记框时,标记框高亮显示,同时高亮显示对应的标签。
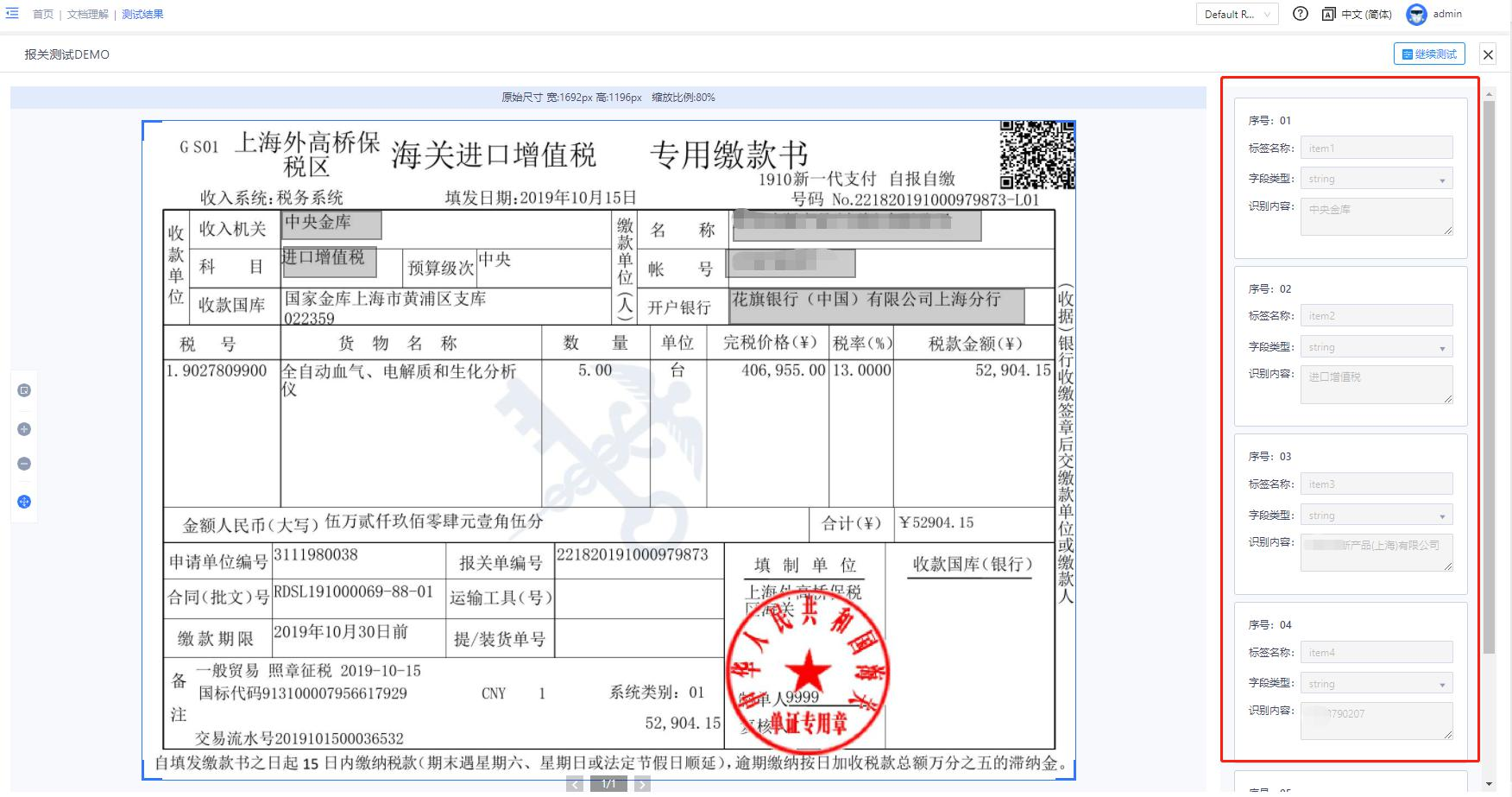
测试文档理解模板
完成模板配置之后我们可以通过测试功能来检查模板的效果,点击“测试”按钮再 弹窗中上传需要进行测试的文件后即可查看新样本的信息抽取结果,在抽取结果页中展示所有的标签项及标签抽取内容。
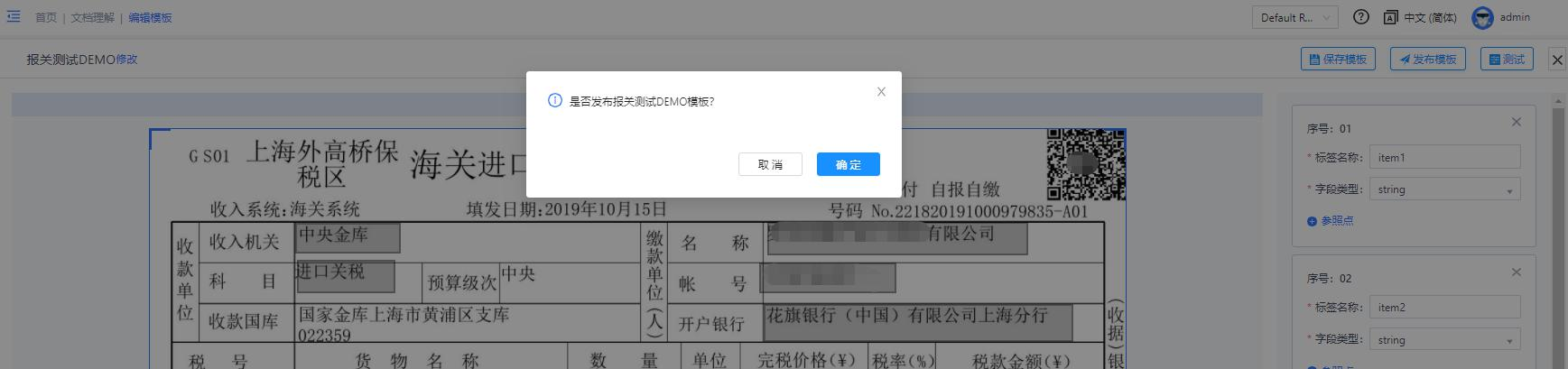
发布文档理解模板
若当前模板测试通过之后,可以在模板配置页或操作选项中点击”操作”按钮即可对当前模板进行发布操作。发布完成之后即可通过 文档理解组件调用 当前模板服务,从而实现 RPA 流程大量抽取非结构化文本信息。