获取多层嵌套的表格中的数据
我们在流程开发中往往会遇到web页面的很多table类元素进行处理的问题,一般我们在网页上需要获取的table(例如n*m类型)表格时,我们可以很方便地借助编辑器中的【获取结构化数据】组件来实现table获取。但是我们也会遇到多层table嵌套导致无法一次性获取整个table然后进行数据处理的情况,下面我们将对这种情况进行探讨。
准备工作
准备开发流程的电脑,请打开云扩学院链接查看云扩RPA编辑器运行的硬件&软件要求(https://academy.encoo.com/wiki/Studio/quickStart/HarewareAndSoftwareRequirements.md?)。
准备流程所需要用到的数据。
案例介绍
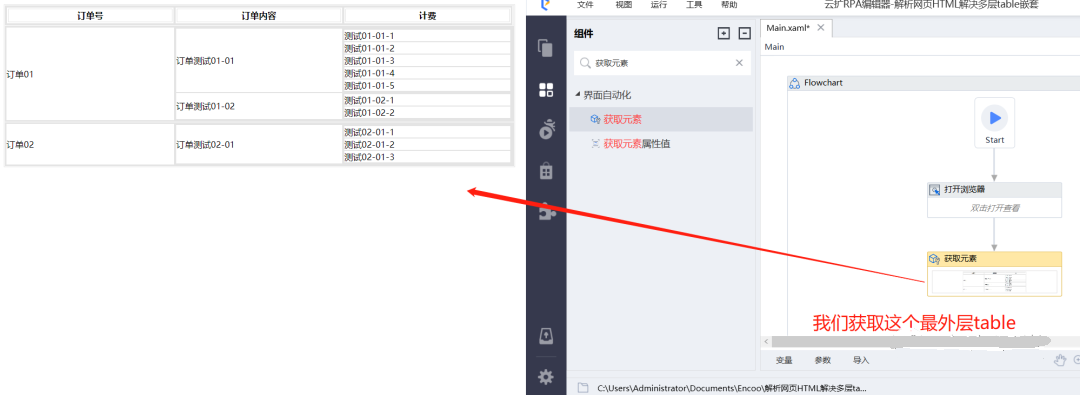
用云扩RPA来进行多层 table 嵌套的 web 表格处理,表格举例如下:
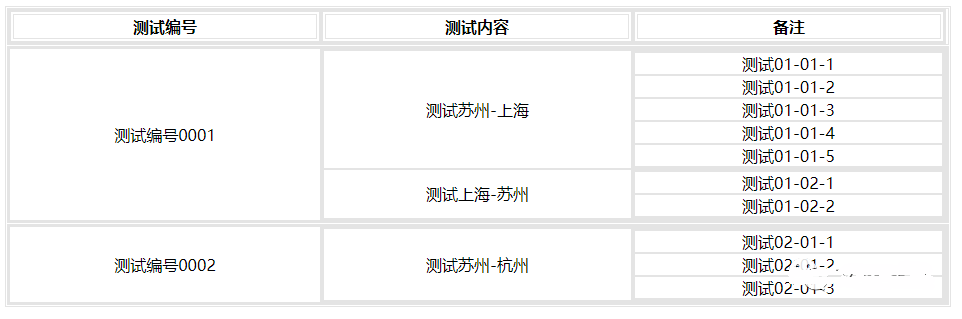
网页源码:
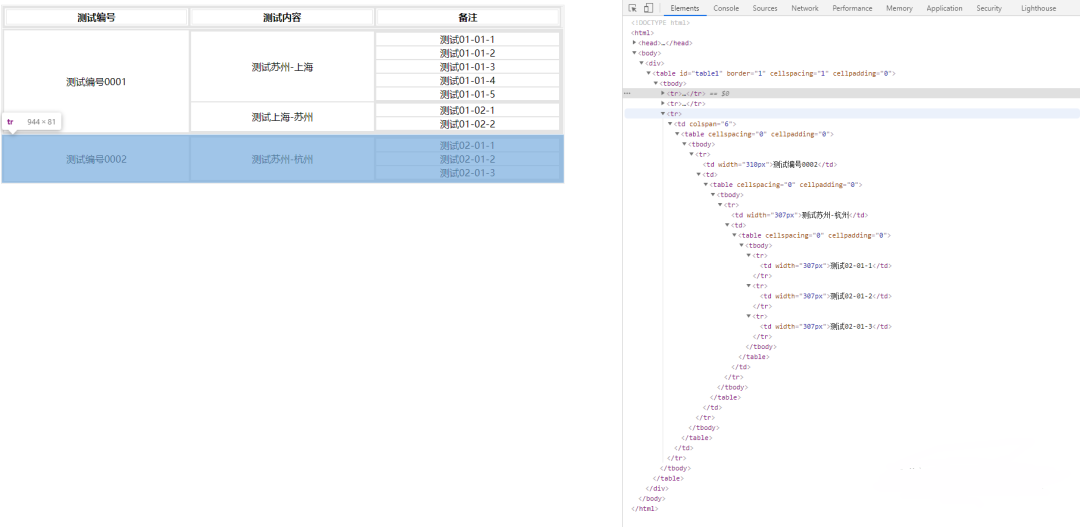
在上述例子中,假设我们需要获取网页中这个表格的最后一列,如果我们使用【获取结构化数据】组件来处理,则无法实现整个table数据的正常获取,此时我们就可以使用如下思路来解决问题。
操作流程
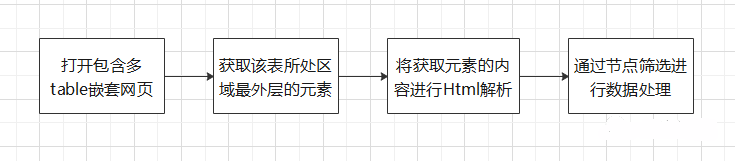
操作步骤
- 打开云扩编辑器,新建项目:
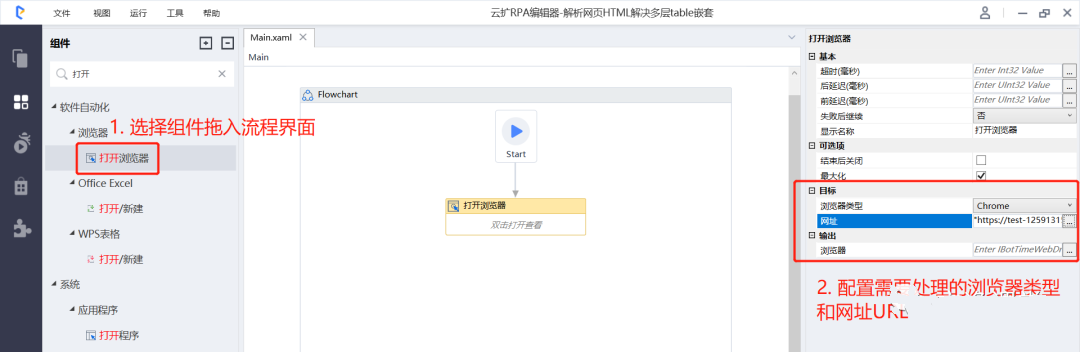
- 添加【打开浏览器】组件,配置需要处理的网页URL:
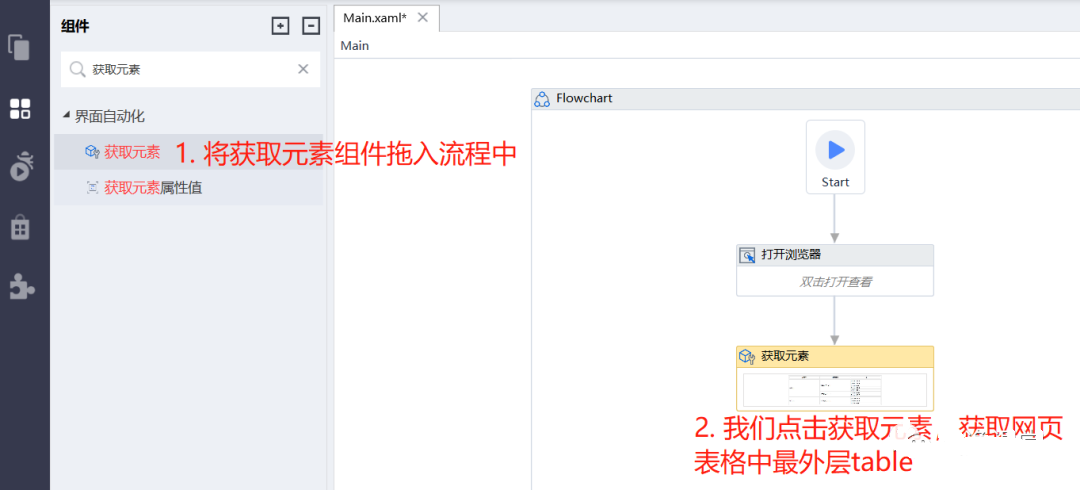
- 添加【获取元素】组件,获取整个table最外层元素信息:

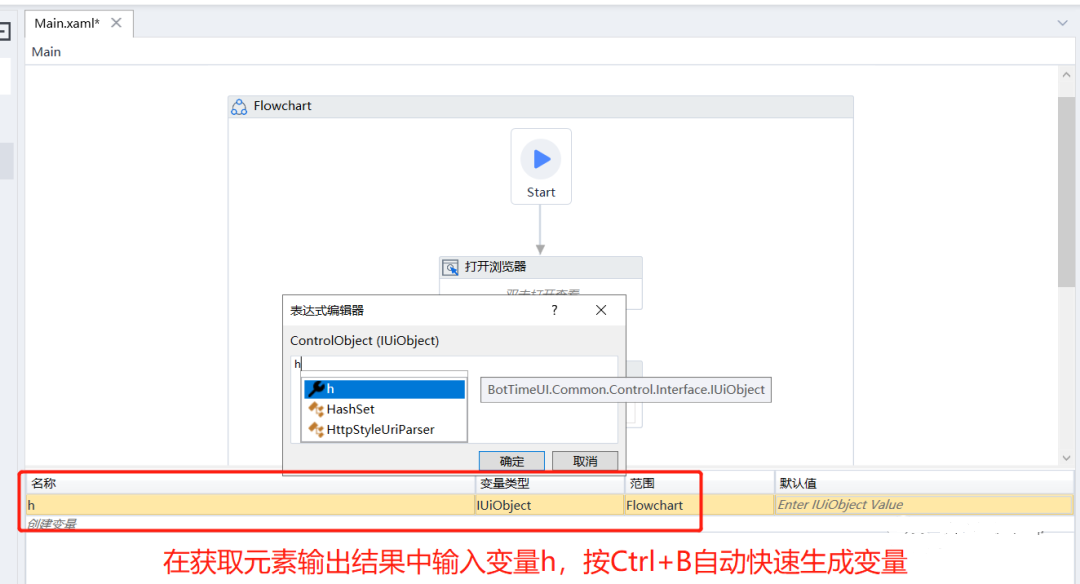
- 将获取元素的输出结果赋值给新变量h(选中变量h,按Ctrl+B可以快速自动创建变量h):
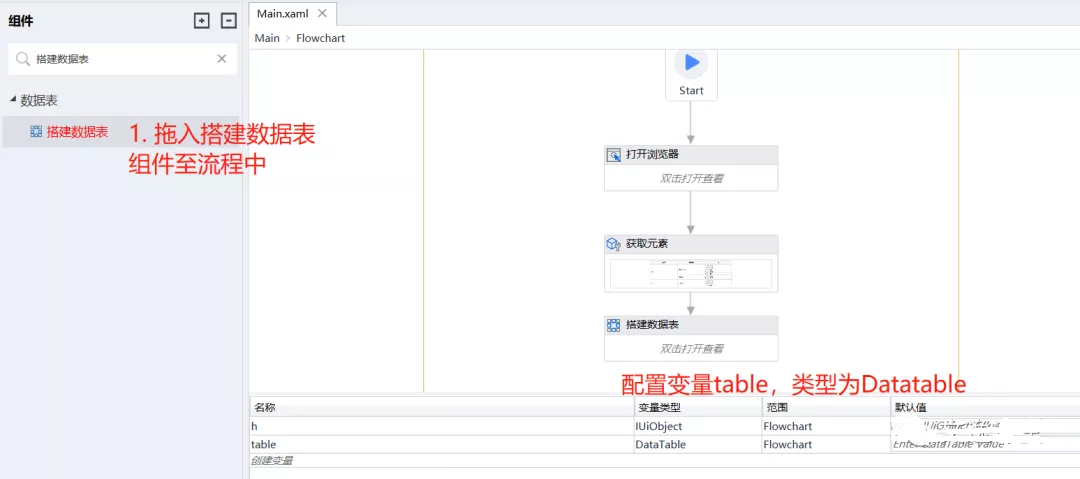
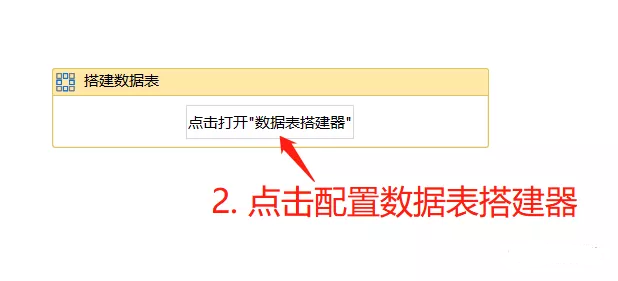
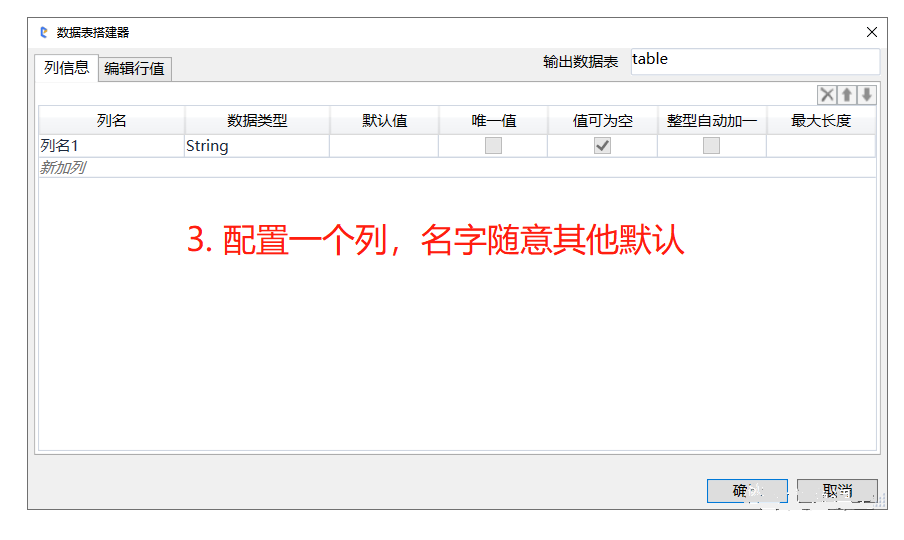
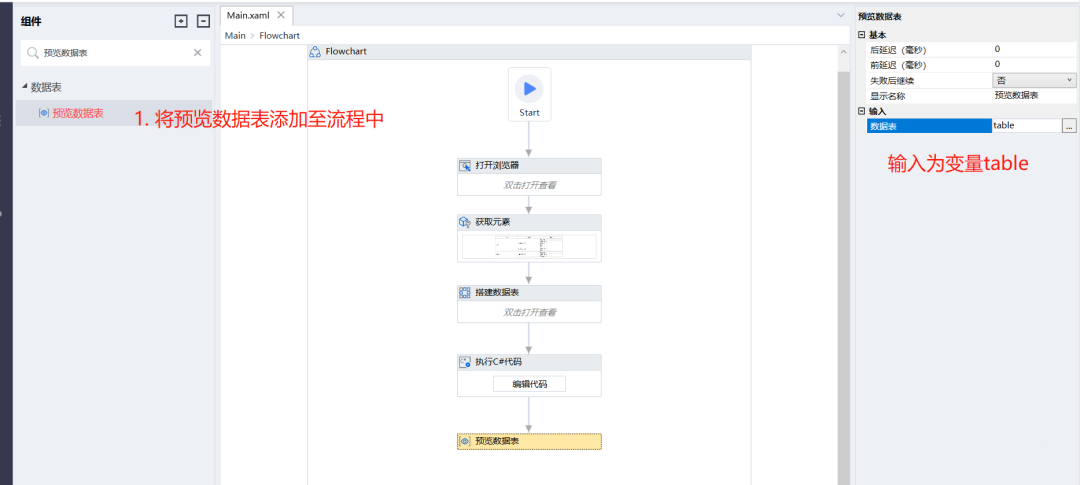
- 为了更明显地展示从web端获取的数据,这里新建一个datatable,配置一个列(string类型,我们假设只需要获取网页中一列数据),来接收网页table获取的所有结果:
- 通过C#代码来处理获取table的元素(即变量h):
try
{
// 使用Html Agility Pack开源组件来进行Html解析
string htmlCode = (h.GetProperty("innerHTML")).ToString();
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(htmlCode);
// 遍历需要获取的信息的节点
// 此处的SelectNodes中Xpath为页面获取元素的这段源码中,需要获取的节点信息的xpath路径
// 请实际使用中用谷歌F12+ Ctrl + F在最下面的输入框中进行调试
foreach (HtmlNode row in doc.DocumentNode.SelectNodes("//table//table//table//tr"))
{
//将节点信息添加到数组中
string[] tdArr = row.SelectNodes("td").Select(td => td.InnerText).ToArray();
// 通过判断条件进行数据信息筛选,此处我们假设我们需要筛选数据内容是字符"2"结尾的内容
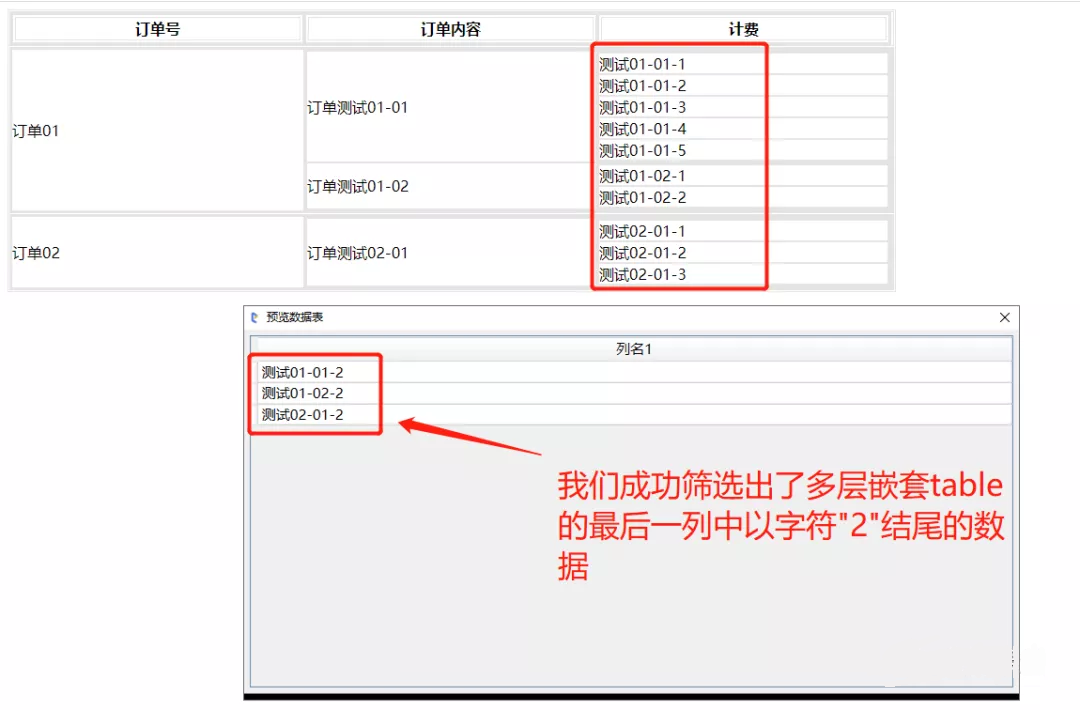
if (Convert.ToInt32(tdArr[0].Substring(tdArr[0].Length - 1)) == 2)
{
// 将筛选内容添加到datatable中
table.Rows.Add(tdArr);
}
}
}
catch(System.Exception e)
{
Console.WriteLine(e.Message.ToString());
}
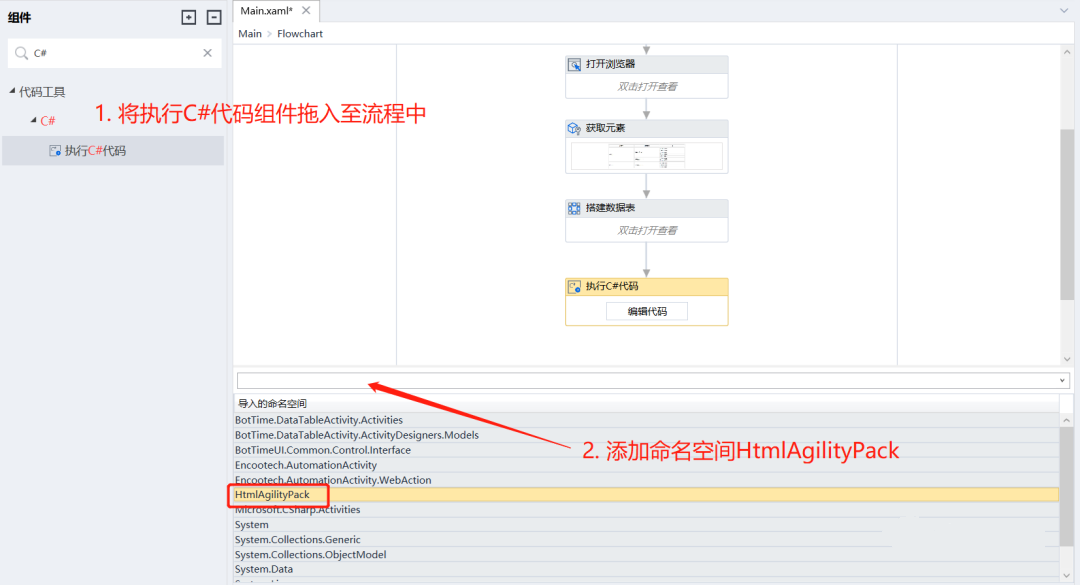
- 我们使用组件【预览数据表】来查看处理结果:
至此,从多层嵌套的table中获取不固定数据的流程已开发完成,保存并运行,执行流程并查看结果对比:
后续操作
- 我们看到执行过程只是简单的进行对多层table这一段源码进行遍历操作,使用的是节点筛选,当我们这里需要处理多个页面时,只要保证这个table嵌套的架构一致,那么我们网页中的节点td(也就是说最后一列的数据)可以是动态的,可以是1行数据,也可以是100行数据,我们都可以通过Xpath模糊查询的结果来进行筛选出来。
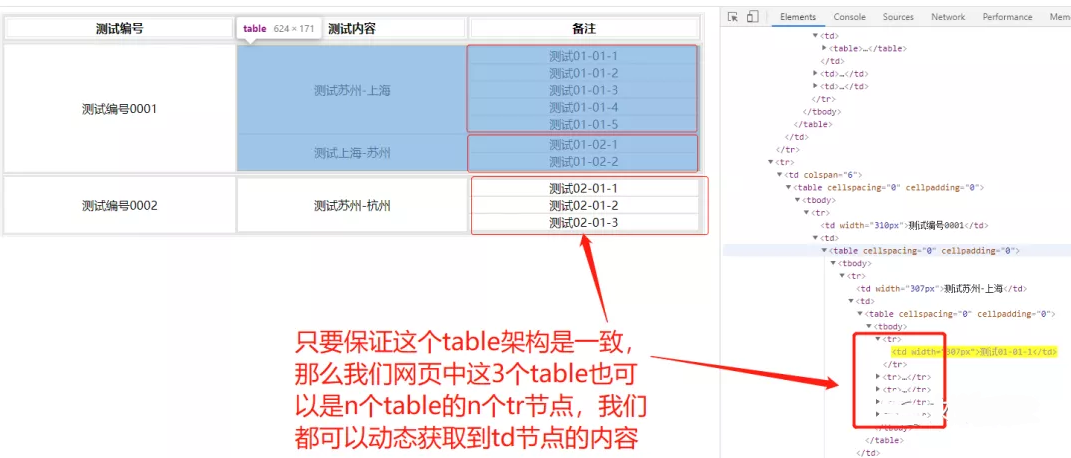
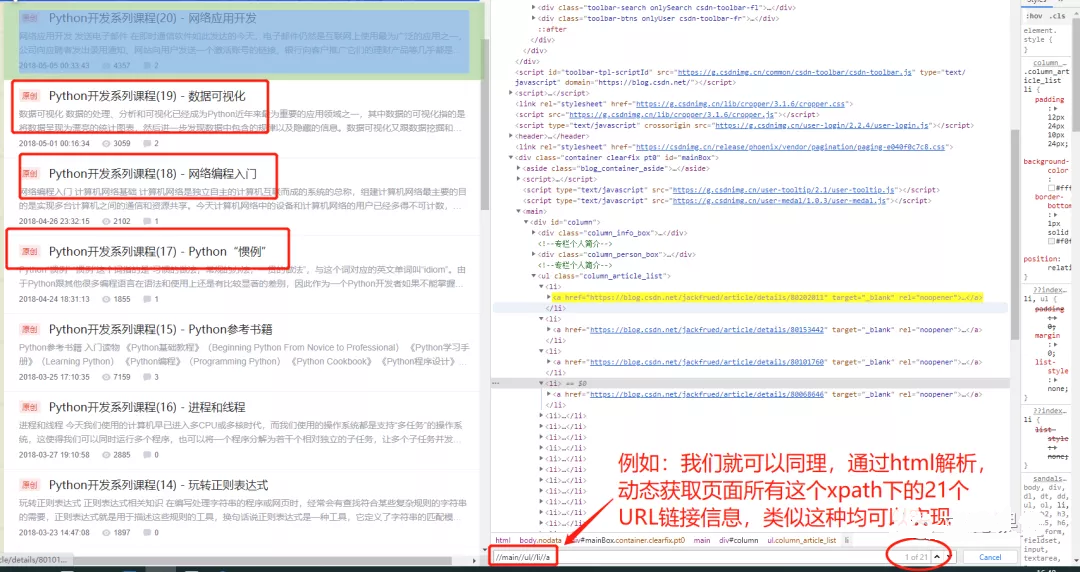
- 综合观点1,我们可以发散,这不仅仅是table可以这样操作,我们这个html的思路,可以使用到任何html页面中想爬取的类似结构,例如下图中情况: