
切割过大 Excel 文件
这节课我们来说说如何用云扩 RPA 来切割有很多行数据的 Excel 文件。
就像此前,在实际项目实施中,我们拿到一个有 50000 多行数据的 Excel 文件,我们在处理时,将其分隔成了多个 5000 行的文件。为什么需要做这样的分割呢?一种情况是,文件太大可能会影响 RPA 在读写文件时的速度(当然影响速度并不是 RPA 本身的问题,我们可以尝试手动打开一个有这么多行数据的 Excel 文件,速度也会很慢。)另一种情况是,有些业务系统只支持一次性处理数据量有限制,比如:企查查批量查询企业信息时明确写着一次最多处理 5000 条数据。
流程详述
在本课程中,你可以将已准备好的一个包含 50000+ 行数据的 Excel 文件按照用户自定义的数据行数切割为多个文件。
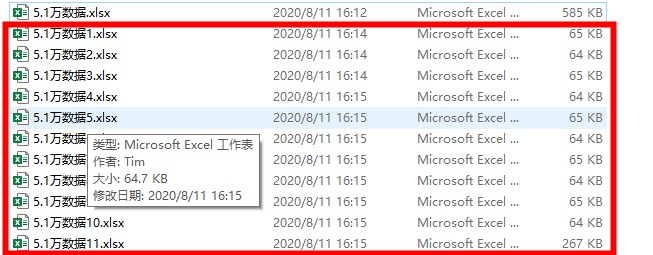
原文件包含在流程文件中,名为 5.1万数据.xlsx。
流程运行完成后(假设文件按5000行/文件进行切割),切割为11个小文件,如图:
如果你希望获取示例流程文件,点击分割过大 Excel 文件获取。
流程实现逻辑
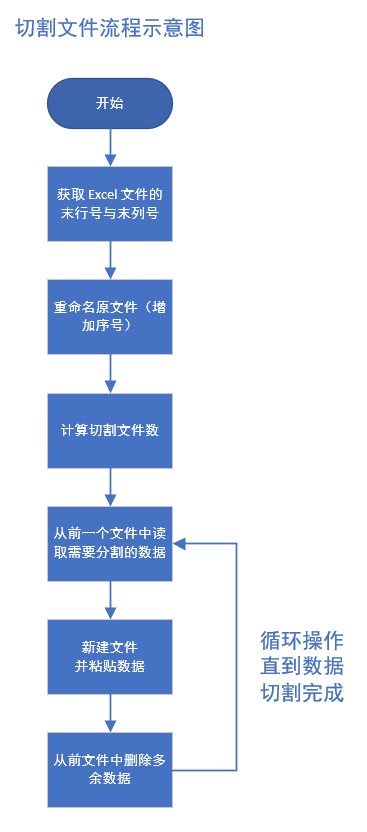
示例流程中使用的是如下图所示的实现逻辑,你可以参考这样的逻辑,甚至实现运行效率更高的流程逻辑。
流程开发步骤
打开云扩编辑器,新建项目
本项目命名为 切割过大Excel文件。
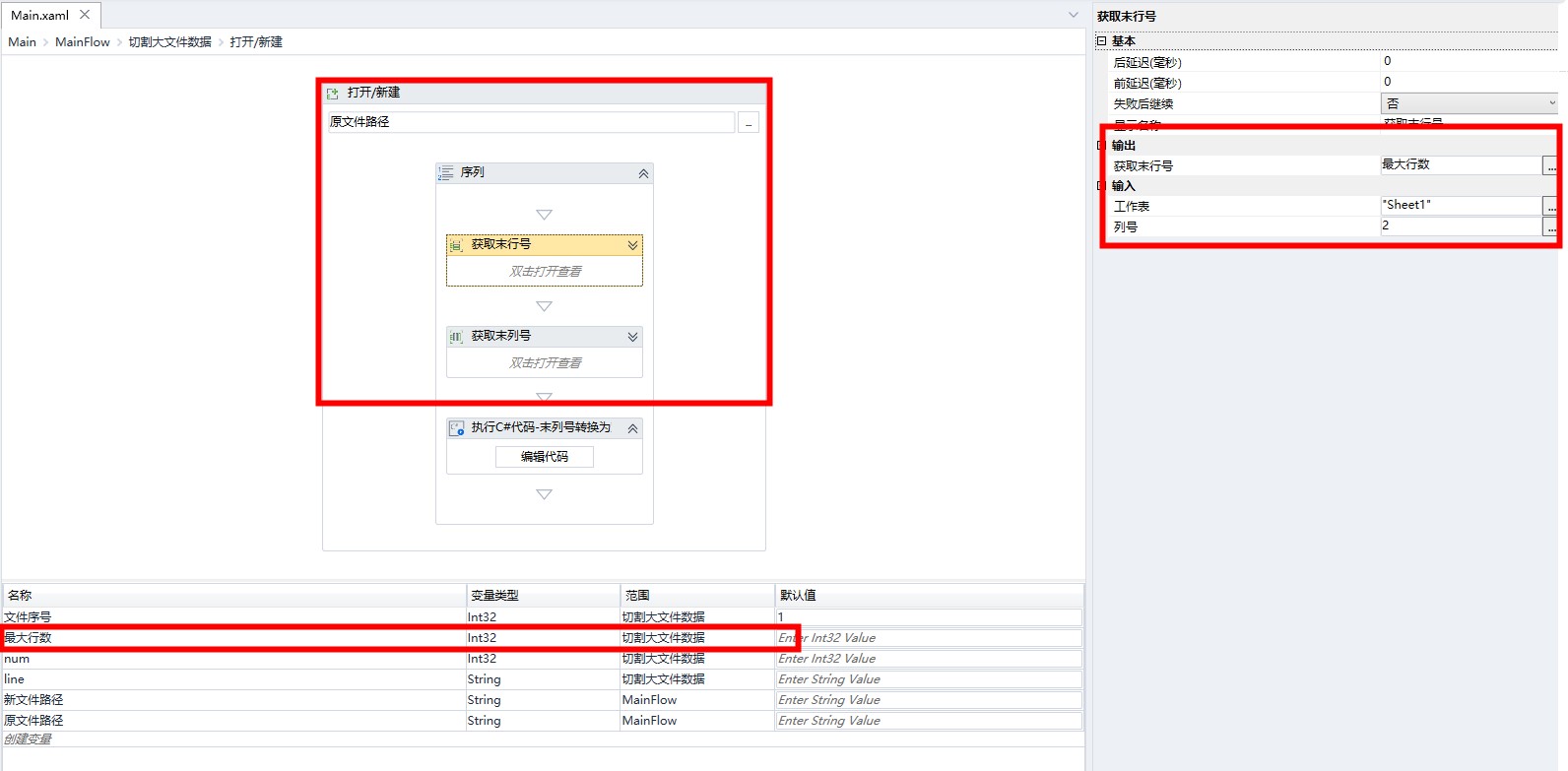
打开 Excel 文件,获取末行号,末列号
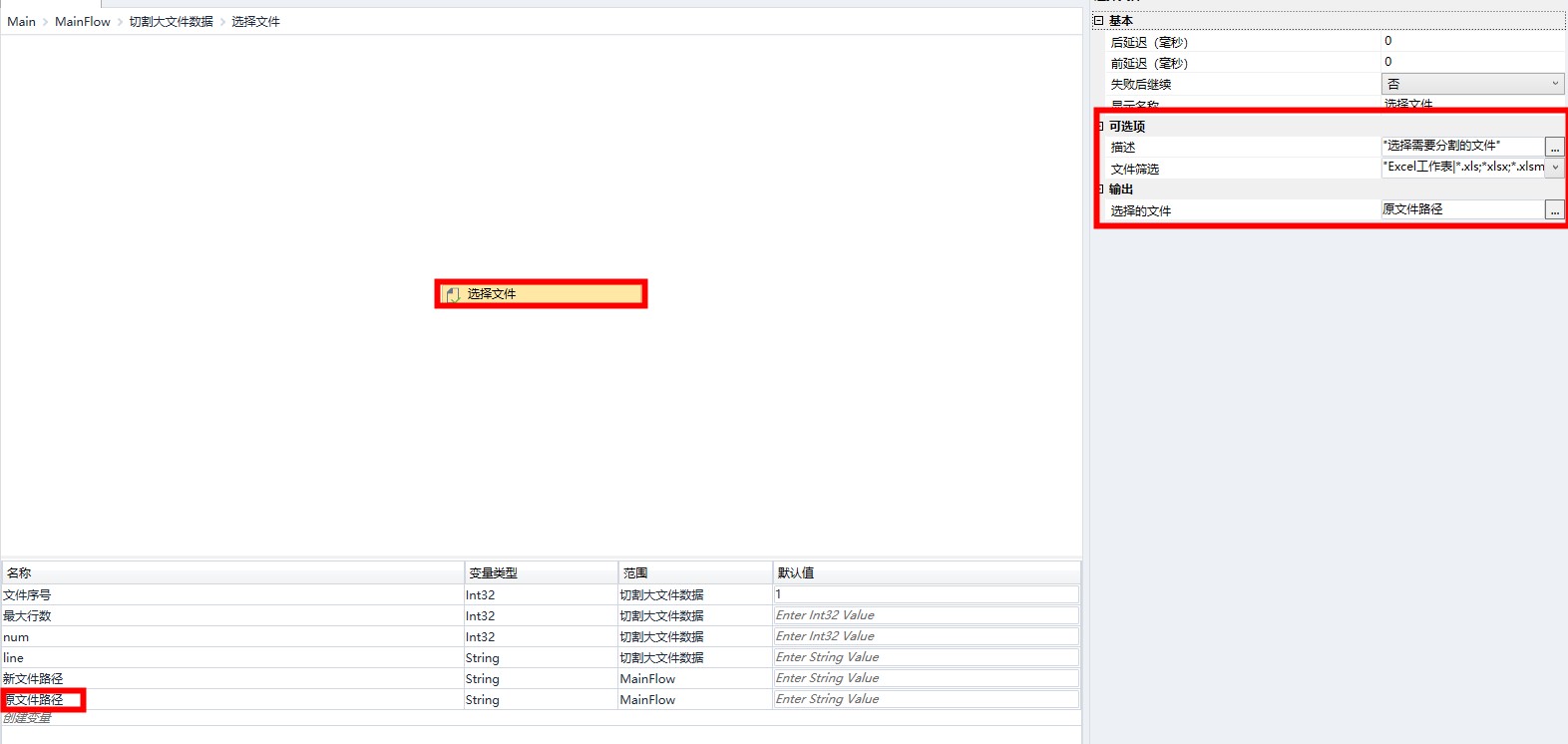
使用选择文件组件,方便输入需要处理的 Excel 文件,并把文件路径存放在变量原文件路径中。
使用该路径打开 Excel 文件,使用已有组件获取末行号和末列号。
将获取的末列号数字转换为 Excel 中对应的列号(字母)。这边,我们使用一小段 C# 代码实现转换:
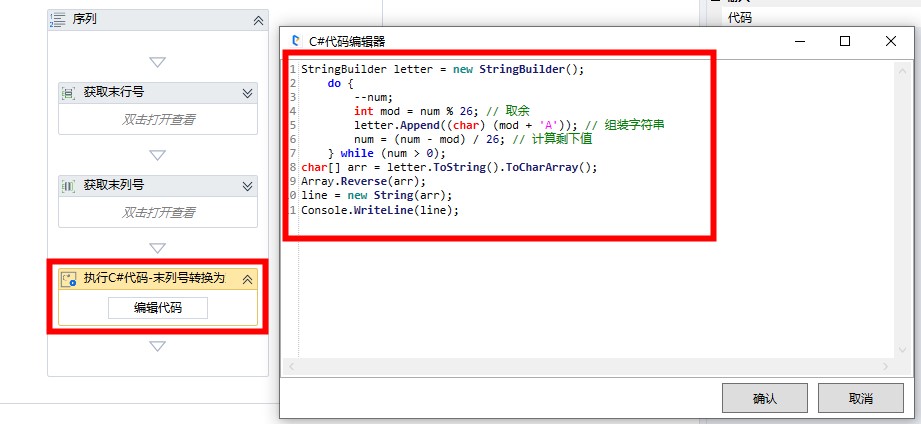
代码参见:
StringBuilder letter = new StringBuilder(); do { --num; int mod = num % 26; // 取余 letter.Append((char) (mod + 'A')); // 组装字符串 num = (num - mod) / 26; // 计算剩下值 } while (num > 0); char[] arr = letter.ToString().ToCharArray(); Array.Reverse(arr); line = new String(arr); Console.WriteLine(line);
更改原文件名
将分割得到的文件路径设置为原文件名称+文件序号的形式。
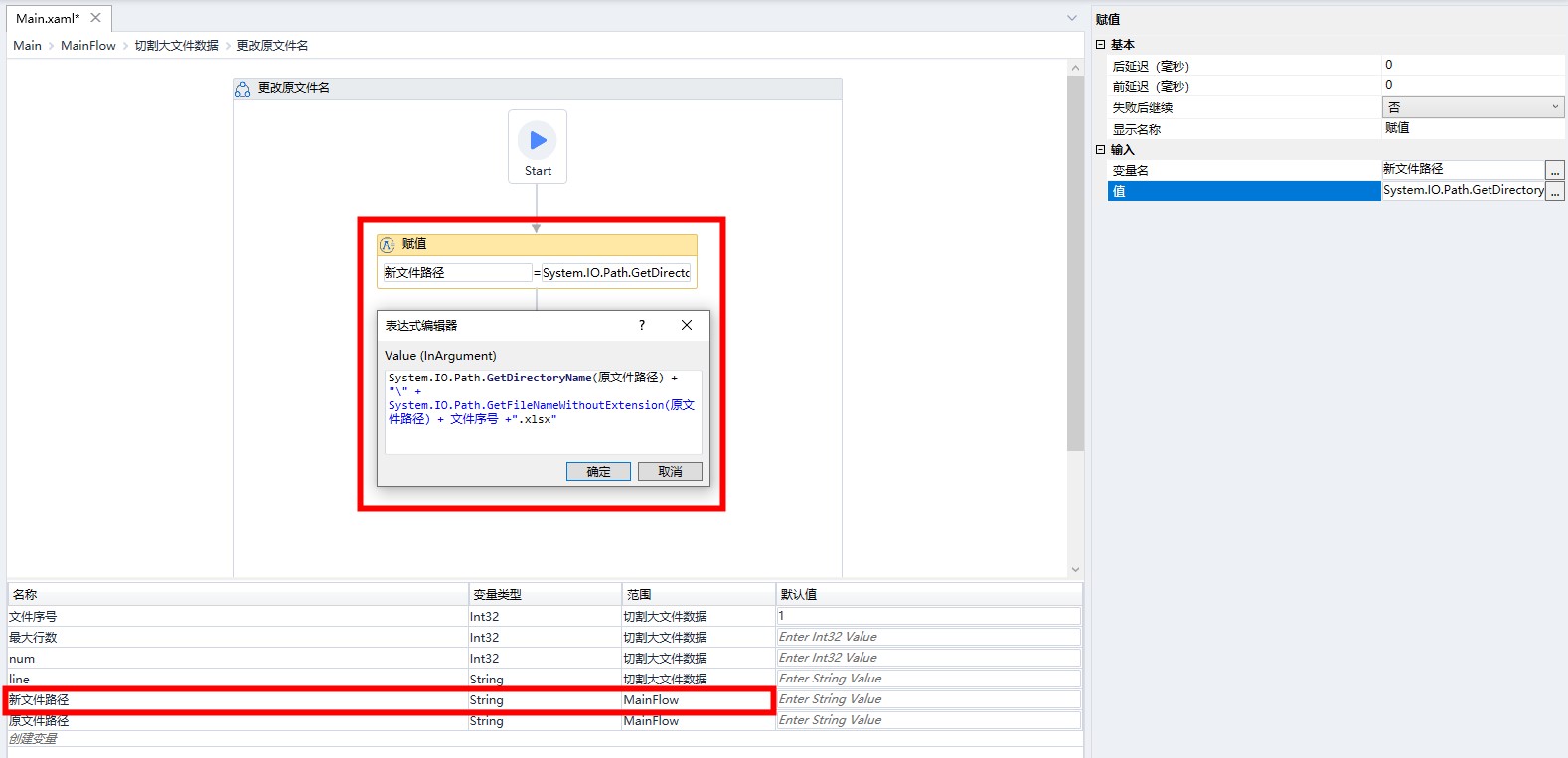
赋值内容是:
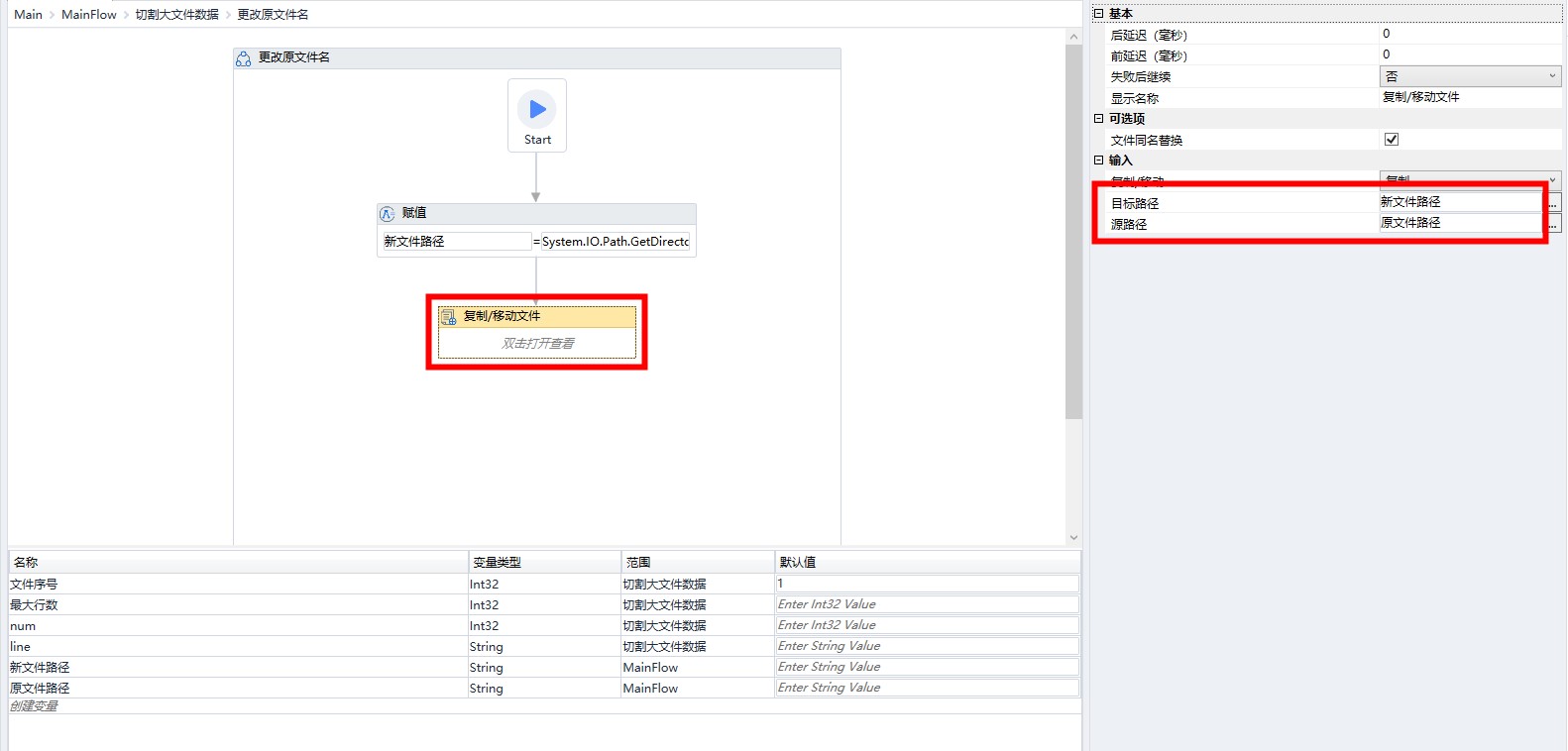
System.IO.Path.GetDirectoryName(原文件路径) + "\" + System.IO.Path.GetFileNameWithoutExtension(原文件路径) + 文件序号 +".xlsx"复制原文件,并将副本命名为文件序号为1的新文件。
计算分割文件数
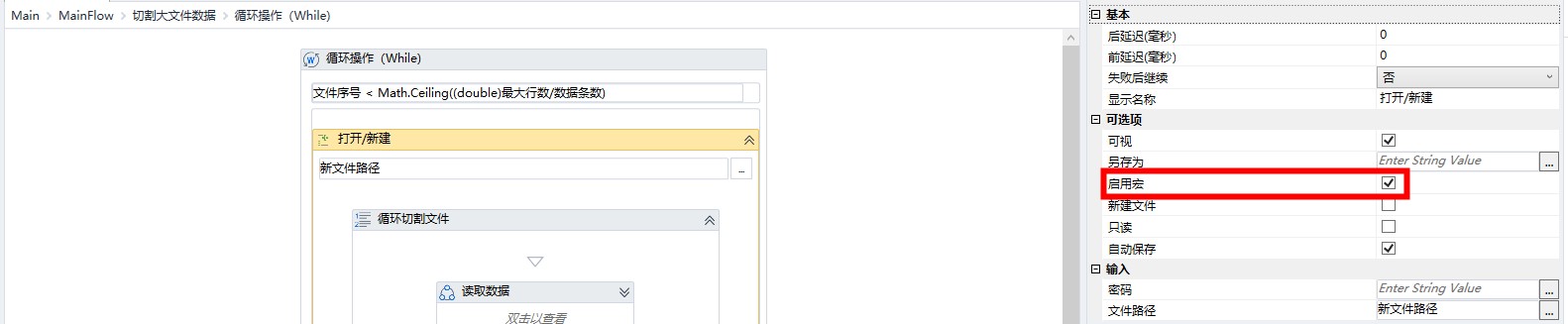
使用循环操作(While)组件,并输入循环条件。
计算循环次数的思路如下:如果原文件数据有65行,且我们希望切割将其切割为含有不超过10行数据的小文件,那么需要需要切割为7个小文件(65 mod 10 + 1 = 7)。

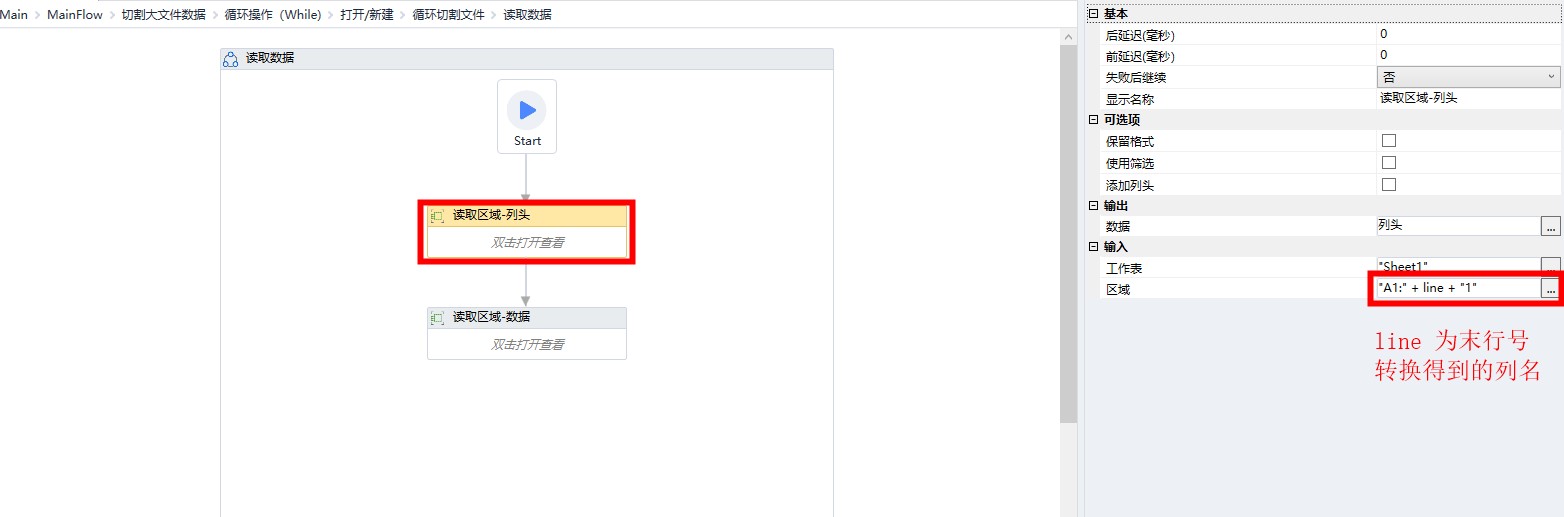
从前一个文件中读取需要分割的部分
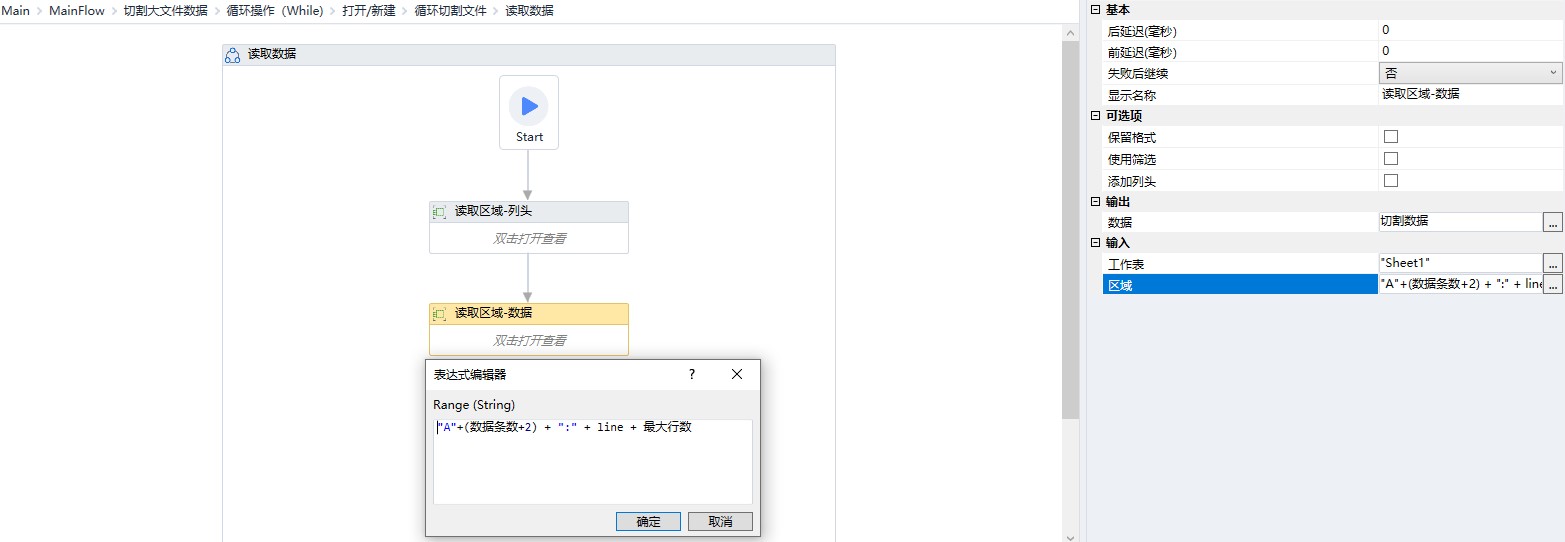
新建文件并写入获取的数据
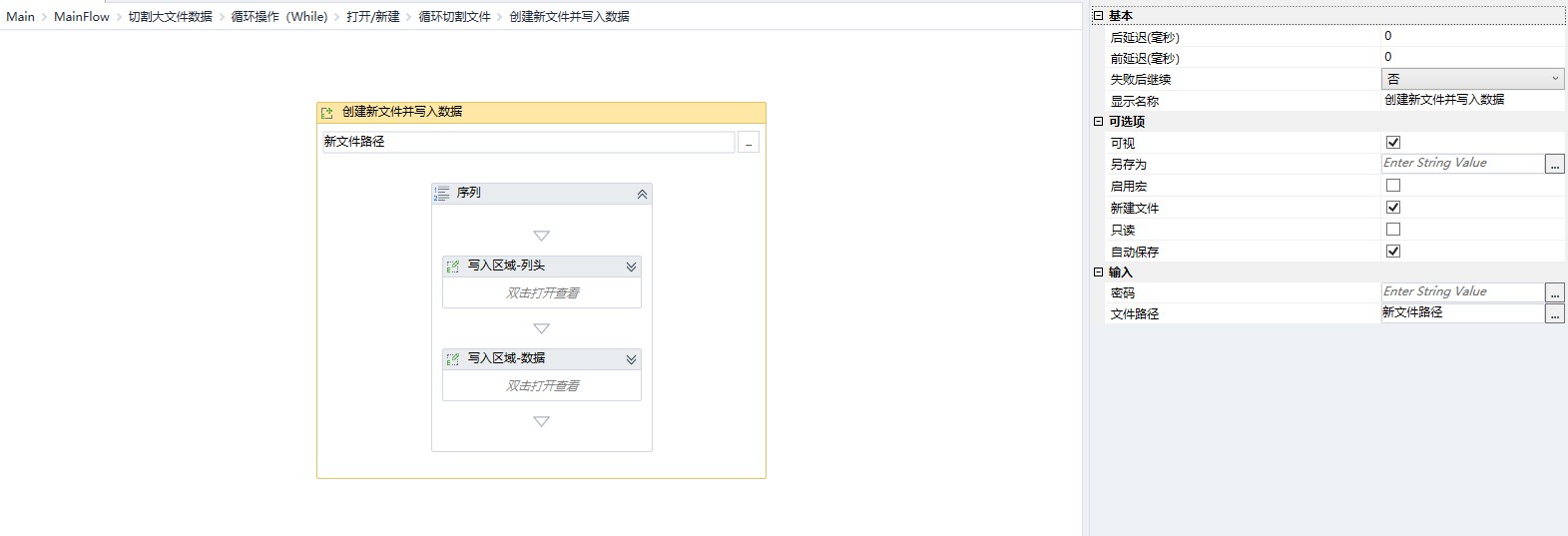
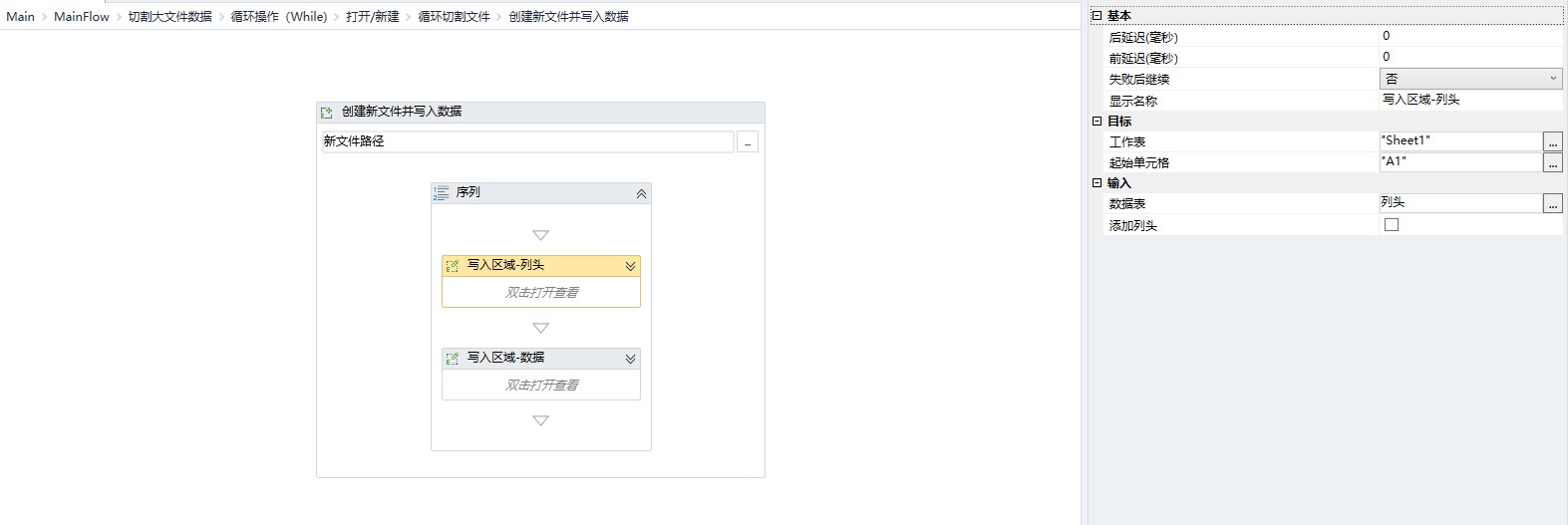

从前一个文件中删除多余的数据
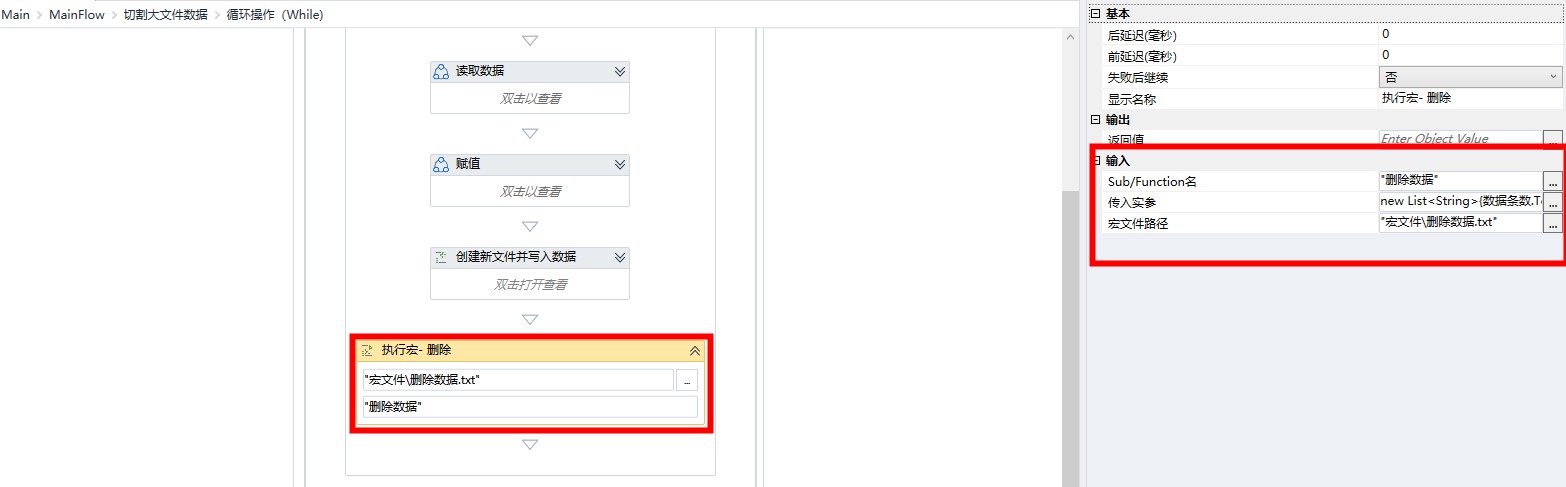
这个步骤我们可以使用云扩提供的 软件自动化->OfficeExcel->删除数据 实现。但鉴于宏的普遍应用需求,此处使用宏实现。
记得在使用打开/新建组件时,勾选启用宏属性。
录制宏并修改。
在执行宏组件中,使用宏文件。
至此,整个流程已完成。