
一、课程简介
【课程目标】
- 恭喜你,晋级为RPA高手只差一步之遥! 本节课程讲带大家学习云扩编辑器中选择器定位元素的实际业务中会遇到的经典业务场景~
- 从Xpath开始,一起挑战下拉框、多选复选框勾选、多层iFrame嵌套网页吧~
- 最后,我们一起学习一下如何根据实际业务场景把一些复杂的业务流程直接打包成组件给一线业务非RPA开发人员使用哦~ 一起让RPA在业务里RUN起来~
课时内容:
- RPA第十六课 (2023年)
- 课程时长:130分钟 ,6节课时
- 编辑器下载:https://www.encoo.com/download
目录:
- 选择器方法3-“XPath”(课程时长:30分钟)
- 宝藏网址”云扩RPA闯关”(课程时长:5分钟)
- 实战技能1--下拉框选项(课程时长:15分钟)
- 实战技能2--多选复选框(课程时长:15分钟)
- 实战技能3--多层嵌套表格(课程时长:25分钟)
- 实战技能4--日期选择控件(课程时长:40分钟)
二、学习内容:
- 选择器方法3-“XPath”(课程时长:30分钟)
- 学习目标:掌握 ★★★
- 难易程度:较难 ★★★★
- 讲义下载:文末进群-获取“讲义PPT”
2.1 “初识”Xpath语法
相信大家在开发网页端系统的业务流程时遇到过用组件获取的元素是以当前元素的id定位的,但该id偏偏是个动态的id,每一次打开页面都会有变化,在这种情况下,除了中级课程中我们提到的寻找稳定特征值之外,我们还可以通过XPath语法对元素进行定位。
所以,这节课我们就来讲讲有关XPath的用法。
注意: Xpath&获取结构化数据 这两种功能是基于网页结构开发的语言/功能,也就是说客户端元素定位,不支持使用“Xpath”或“获取结构化数据”功能对元素进行定位。
一般在Google Chrome开发者工具(按F12)的Elements面板中,使用箭头工具点击相关元素,鼠标右键菜单中选择【Copy】->【Copy XPath】就可以看到XPath,
针对比较简单的网页可以使用此方法,但对于上述提到的动态id,比如阿里云国际站,如下图所示:

当然,在很多实际项目中,比如企查查网站,针对不同的企业类型,相同的元素使用上述方法获取XPath是不同的;
BOSS直聘,针对不同账号,相同的元素使用上述方法获取XPath也不同,那么怎么样才能更精确的定位元素或者避免定位元素出错呢?请看下面的详细讲解。
准备工作:
- 准备开发流程的电脑,请打开云扩学院链接查看云扩RPA编辑器运行的硬件&软件要求
- 打开云扩官网下载编辑器并安装
2.1.1 什么是Xpath ?
XPath是XML的路径语言,通俗一点讲就是通过元素的路径来查找到这个标签元素。
2.1.1.1 工具
查找Xpath推荐使用Google Chrome浏览器,用Chrome打开网页,在空白处右击,点击检查,可以调出开发者工具面板

2.1.1.2 初级获取XPath方法及调试方法
(1). 初级获取XPath方法
在Google Chrome中Elements面板,使用箭头工具点击元素;在Elements面板中悬停在查找到的位置,然后鼠标右键菜单中选择【Copy】->【Copy XPath】;
例如BOSS直聘,推荐牛人按钮的XPath为:
//*[@id="main"]/div[1]/div/dl[2]/dt/a


(2). XPath调试方法
在Elements面板中按Ctrl + F调出查找框,输入XPath,若看到高亮黄色并且只能查找出1个(1 of 1 代表只能查找出1个)时说明此XPath可以被使用。

(3). XPath建议使用方法
上面我们看到了初级获取XPath方法及调试方法,针对实际项目中,由于账号变化、id动态变化等因素,可能导致网站结构变化,XPath即变动了,上述方法存在一定的失败率。下面介绍几种建议的方法。
(4). XPath最有用的路径表达式

(5). 实例
方法1、标签+属性定位
(XPath= "//标签名[@属性='属性值']")- 通过ID定位
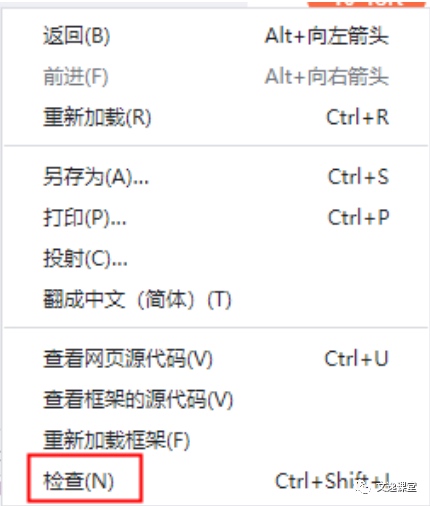
//*[@id='kw']或者//input[@id='kw']

- 通过Class定位
//*[@class='s_ipt']或者//input[@class='s_ipt']
- 通过Name定位
//*[@name='wd']或者//input[@name='wd']
- 通过ID定位
方法2、XPath文本、模糊、逻辑定位
- 文本定位(使用
text()文本函数)
文本定位通常建议在没有多语言的环境中,文本不会由于其他原因变动。
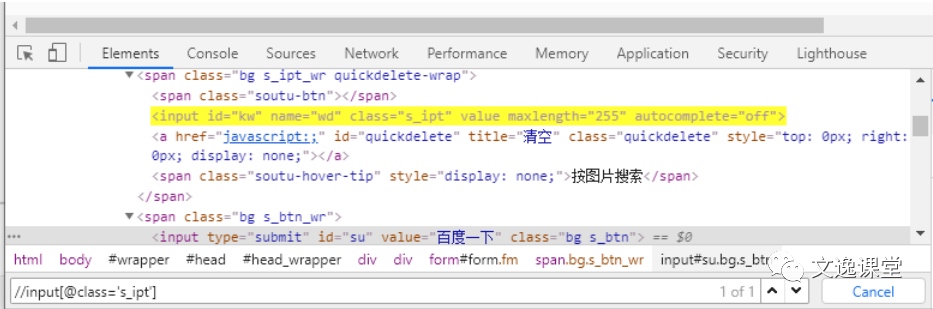
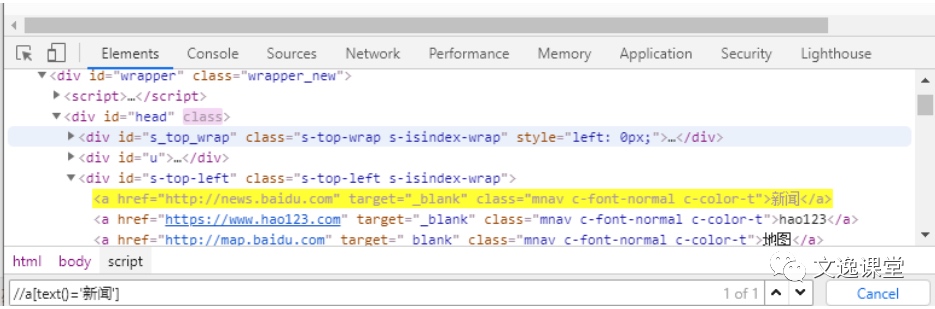
例如,百度首页的新闻超链接的XPath可以表示为//a[text()='新闻']
- 模糊定位(使用
contains()包含函数)
文本模糊定位: 例如,百度首页的新闻超链接的XPath可以表示为
//a[contains(text(),'新')]
属性模糊定位: 例如,百度首页的新闻超链接的XPath可以表示为
//input[contains(@class,"ipt")]
使用逻辑运算符:当单一的属性无法确定到一个元素时,可以使用逻辑运算符。例如,百度首页的输入框可以表示为
//*[@id="kw" and @name="wd"]附: XPath在RPA组件定位器中的写入方式:

- 文本定位(使用
以上就是XPath的基础内容,但是仅仅通过:
- 方法1:标签+属性定位
- 方法2:XPath文本、模糊、逻辑定位
这2种方法不足以覆盖到大部分场景,下面我们讲解如何通过:
- XPath层级”及“指定节点索引”定位
- XPath“轴定位”
2.2 Xpath语法“进阶”
上面我们讲解如何通过XPath"层级及指定节点索引定位"和"XPath轴定位",请看下面的详细内容。
方法1、XPath层级及指定节点索引定位
层级定位: 如果一个元素无法通过自身的属性定位到,那么可以先定位到它的上一级或者上N级,然后再一级一级地找到它,以BOSS直聘为例,找到沟通中的第一个人,XPath为:
//div[@class='sec-content chat-group-full']/div/div/ul[@class='main-list']/li[1]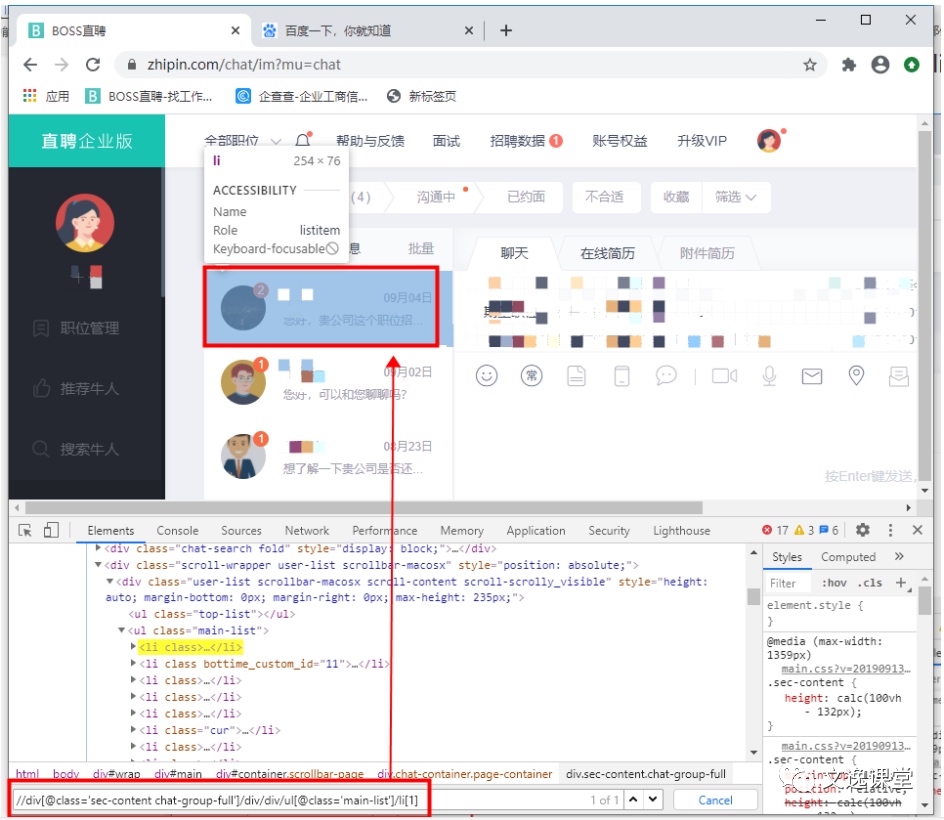
指定节点索引定位:
以BOSS直聘为例,参考上图,需要获取每一个候选人文本,这时需要增加循环,把1作为变量,依次递增,就可以循环遍历每一个人,XPath参考:
"//div[@class='sec-content chat-group-full']/div/div/ul[@class='main-list']/li[" + i + "]"遍历获取候选人参考流程:

获取文本组件,打开选择器窗口,把XPath以变量方式赋值进去,格式:{变量},如下图所示:
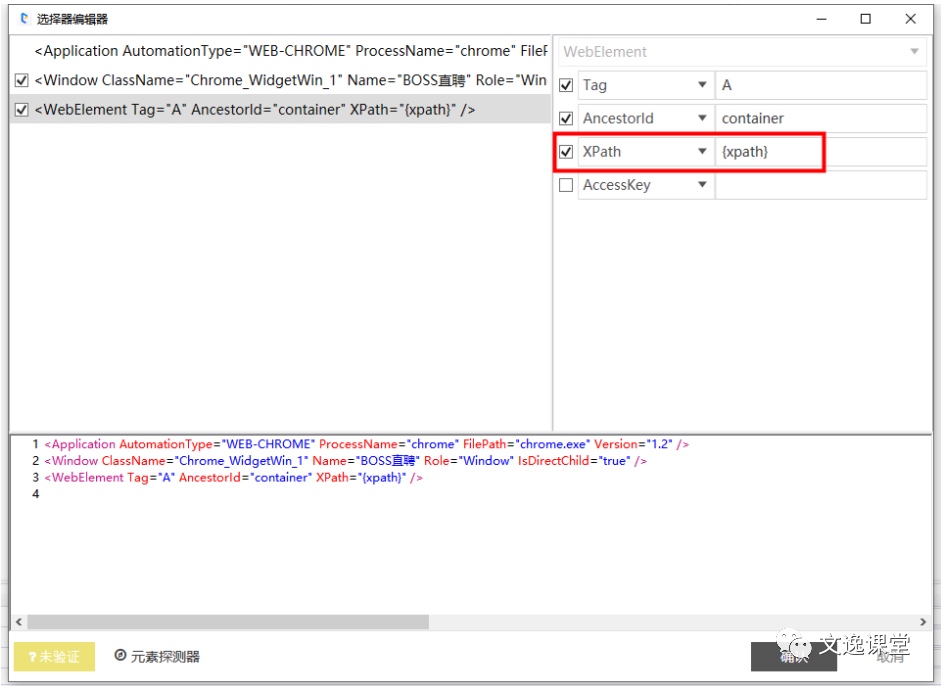
方法2、XPath轴定位
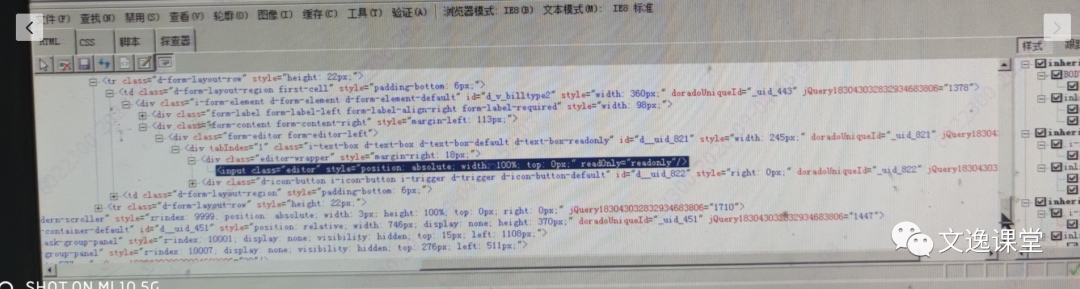
参考下图,此网站源码只有class属性,而且使用class属性不能定位到唯一元素。
这时候我们可以使用XPath轴定位,应用场景是当某个元素的各个属性及其组合都不足以定位时,那么可以利用其兄弟节点或者父节点等各种可以定位的元素进行定位。
轴的意思是相对于当前结点的节点集,使用语法:
轴名称 :: 节点名称
- parent 选取当前节点的父节点,也就是当前节点上一级节点
示例:
//a[text()='新闻']/parent::div前半段
//a[text()='新闻']找到内容为新闻a节点,然后它的上一级节点parent::div,即黄色部分
- child 选取当前节点的子节点,也就是当前节点的下一级节点
示例:
//div[@id='s-top-left']/child::a[1]前半段
//div[@id='s-top-left']为找到属性div中id=s-top-left节点,然后它的下一级节点child::a[1]([1]代表取第一个),即黄色部分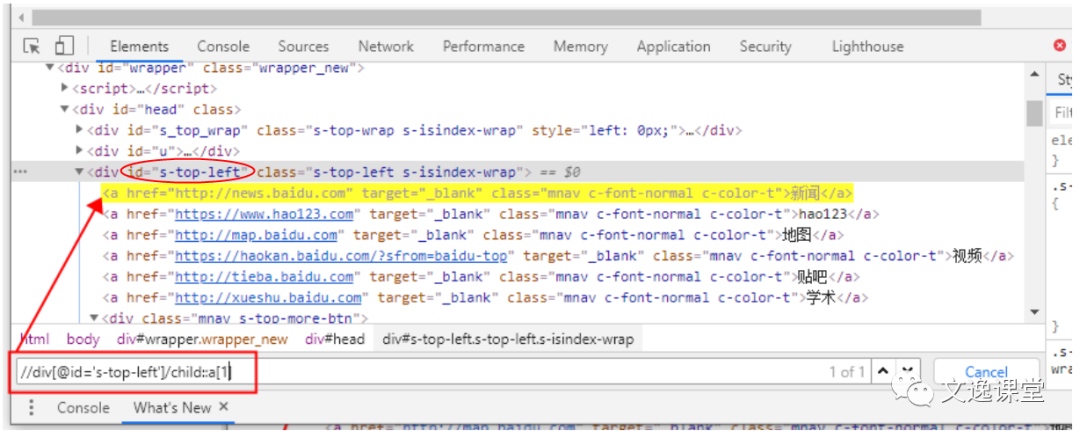
- ancestor:选取当前节点的所有祖先节点(包括⽗节点)
示例:
//span[text()='换一换']/ancestor::div[1]前半段
//span[text()='换一换']为找到内容为换一换的span节点,然后它的上层节点中的所有div节点ancestor::div[1]([1]代表取第一个),即黄色部分
- descendant 选取当前节点的所有下层节点
示例:
//div[@class='s-hotsearch-title']/descendant::a[1]前半段
//div[@class='s-hotsearch-title']为找到属性div 中class=s-hotsearch-title节点,然后它的下层节点中的所有a节点descendant::a[1]([1]代表取第一个),即黄色部分
- following 选取当前节点之后显示的所有节点
示例:
//a[text()='新闻']/following::a[1]前半段
//a[text()='新闻']找到内容为新闻a节点,然后它的当前节点之后显示的所有a节点following::a[1]([1]代表取第一个),即黄色部分
- following-sibling 选取当前节点之后所有的兄弟(平级)节点
示例:
//a[text()='新闻']/following-sibling::a[1]前半段
//a[text()='新闻']找到内容为新闻a节点,然后找到它的兄弟节点之后所有a节点following-sibling::a[1]([1]代表取第一个),即黄色部分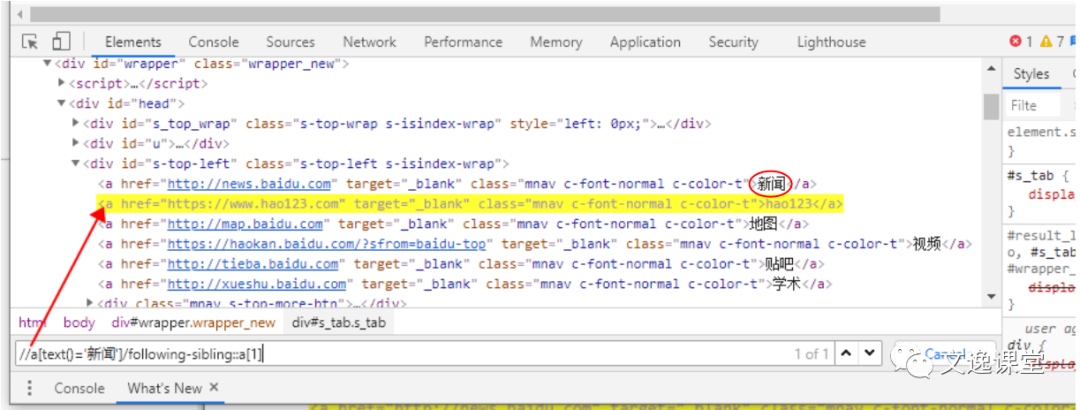
- preceding 选取当前节点前面所有的节点
示例://a[text()='新闻']/preceding ::a[3]
前半段//a[text()='新闻'] 找到内容为新闻a节点,找到前面所有节点中的a节点preceding ::a[3]([3]代表取第三个),即黄色部分

- preceding-sibling 选取当前节点前面所有兄弟(平级)节点
示例:
//div[@id='s-top-left']/preceding-sibling::div[1]前半段
//div[@id='s-top-left']为找到属性div 中id=s-top-left节点,然后前面的所有兄弟节点中的div节点preceding-sibling::div[1]([1]代表取第一个),即黄色部分
写在Xpath最后,以下为初学者在定位一个元素时的建议:
1. 优先查看能否直接通过元素唯一属性来定位, 例如
//input[@id='kw']
//input[@class='s_ipt']
//input[@name='wd']
2. 如果不能直接通过元素属性唯一定位,尝试通过文本,层级及指定节点索引来唯一定位, 例如
//a[text()='新闻']
//a[contains(text(),'新')]
//div[@class='sec-content chat-group-full']/div/div/ul[@class='main-list']/li[1]
3. 当某个元素的各个属性及其组合都不足以定位时,那么可以利用其兄弟节点或者父节点等各种可以定位的元素进行定位,然后在来找你要定位的元素,例如
//a[text()='新闻']/parent::div
//a[text()='新闻']/following-sibling::a[1]
好啦,以上就是Xpath的全部课程内容,同时Xpath本身和Sql一样是一门技术语言 ,云扩仅作为工具集成了Xpath,支持通过Xpath进行元素定位。
Xpath本身需要一些学习时间成本,同学们且稍安勿躁,根据业务需求静下心来好好学习~ 相信学会Xpath的你,在面对99%的网页元素问题的时候都可以迎刃而解啦 ~
END:
